

0. 시작하며
서비스를 개발, 배포를 해보니 자연스럽게 누가 언제 얼마나 내 서비스를 사용하는지 궁금할 때가 있었습니다. 이런 생각을 같이 하고있던 팀원들과 함께 서비스 로그를 수집하고 분석하여 제공하는 대시보드 프로젝트를 진행했는데요. 이때 사용했던 InfluxDB에 대해 정리하려합니다.
1. 후보군
https://www.influxdata.com/comparison/
Compare Popular Databases
See how the most popular databases compare to each other on prices, features, scalability, and more using this side-by-side comparison.
www.influxdata.com
InfluxDB의 공식페이지에서는 상용중인 여러 DataBase들과의 비교한 글을 볼 수 있었습니다.
위 페이지 글을 기반으로 몇가지 로그데이터를 저장할때 좋다는 DB들을 추려서 비교를 진행 해 보았고 짧게 표현하자면 다음과 같습니다.
- MySQL
- 장점
- ACID(원자성, 일관성, 격리, 내구성) 속성을 준수하여 데이터 무결성 및 일관성
- 수직 및 수평으로 확장
- 마스터-슬레이브 및 마스터-마스터 복제를 비롯한 다양한 복제 기술을 지원하여 높은 가용성과 내결함성 등..
- 단점
- 대규모 시계열 데이터에는 효율적이지 않음, 고쓰기 처리량이나 저지연 쿼리에 대응하기 위해 많은 사용자 정의 필요.
- 장점
- Mongo DB
- 장점
- TTL 인덱스 및 최근 추가된 사용자 정의 열 저장 엔진 지원.
- 단점
- 일반적인 data를 다루기때문에 새로운 메트릭을 추가하거나 기존 메트릭을 수정하는 등 전용 시계열 데이터베이스만큼 시계열 데이터에 최적화되지 않음.
- 장점
- TimeScale DB
- 장점
- PostgreSQL을 기반으로 구축, 수평 확장성, 열 저장소, 보존 정책 지원. 시계열 데이터 관리에 유리.
- 단점
- 매우 높은 쓰기 처리량이나 실시간 분석이 필요한 애플리케이션에는 influxDB가 유리함
- 쓰기 성능이 influxDB가 더 뛰어남
- 유료
- Timescale DB VS InfluxDB의 홈페이지엔 각 DB의 비교글이 존재합니다. 두 글 모두 읽어보시고 선택에 참고하시면 도움이 될 것같습니다
- https://www.timescale.com/blog/timescaledb-vs-influxdb-for-time-series-data-timescale-influx-sql-nosql-36489299877/
- 장점
- 카산드라
- 장점
- 분산 광(넓은) 열 데이터베이스, peer-to-peer 아키텍처. 시계열 데이터 처리에 유용. 수평 확장 가능, 고가용성을 위한 데이터 복제 지원.
- 단점
- 데이터 일관성과 성능 사이의 균형 조절이 어려울 수 있음. 개발자가 코드레벨에서 해야할일이 많아짐
- 장점
- 엘라스틱서치
- 장점
- 분산 검색 및 분석 엔진. 다양한 데이터 유형 처리에 적합. 강력한 전문(full-text) 검색 기능, 수평 확장 가능, 다양한 집계 연산 지원.
- 단점
- 전용 시계열 데이터베이스만큼 시계열 데이터에 최적화되지 않음.
- 장점
2. 왜 InfluxDB인가?
InfluxDB의 장점
- Telegraf
- 입력(input), 처리(processor), 집계(aggregator), 출력(output) 동작 다양한 서비스와 연동하여 사용할 수 있도록 해주는 에이전트입니다.
- 이를 통해 다양한 서비스들과 연동이 용이하다고 합니다.
- 해당 프로젝트에서 Kafka와함께 write기능을 수행했습니다.
- Apache Parquet 사용
- Apache Hadoop 생태계 및 여러 대형 데이터 시스템과 프로젝트에서 데이터 교환을 위해 사용되고 있습니다.
- 효율적인 데이터 저장 및 검색 : 사전 및 실행 길이 인코딩(RLE)을 포함해 다양한 데이터 유형을 효율적으로 저장하고 검색합니다.
- 성능 및 압축의 이점: 쿼리를 수행할 때 열의 일부를 스캔할 수 있기 때문에 I/O 및 계산이 줄어듭니다.
- 데이터 저장 방식: 필요한 열의 하위 집합만 쿼리함으로써 대규모 쿼리에서 이점이 있습니다.
- SQL과 인플럭스QL 쿼리 언어를 모두 지원하여 학습곡선이 비교적 낮습니다.
- TSM ( Time-Structured Merge Tree ) 구조로서 시계열 데이터에 최적화 되어있습니다.
- 보존 정책, Task동작을 지원합니다.
- HTTP API를 지원합니다
- 오픈소스이며, 공식문서가 잘 구성되어있습니다.
InfluxDB 단점
- insert의 경우 TSM 구조를 가지고 있어 high cardinality의 경우 성능이 저하될 수 있습니다.
- Flux라는 Query Language를 사용해야합니다.
해당 프로젝트의 구조는 서비스에서 로그데이터를 수집하고 이를 분석해야합니다. 따라서 시간을 기반으로 압축, 정렬, 샤딩 등의 기능을 기본적으로 수행할 수 있는 "시계열 DB"가 적합하다고 생각했습니다.
그 중에서도 오픈 소스로서 활발한 생태계를 가졌으며 실시간 환경에서 적합한 InfluxDB를 선택하여 진행했습니다.
3. 데이터 모델 및 관리
https://docs.influxdata.com/influxdb/v2/reference/key-concepts/data-elements/
InfluxDB data elements | InfluxDB OSS v2 Documentation
Thank you for your feedback! Let us know what we can do better:
docs.influxdata.com
데이터 모델
Influx DB는 하나의 버킷내에 여러 Measurement가 있고 각 필드를 구성할 수 있습니다. (Measurement는 RDB의 table 과 비슷합니다.)
필드는 tag set, field set 으로 이루어지는데 tag의 경우 index설정이 되고 String값으로 Key,Value 쌍을 가집니다. field의 경우 Key는 String, Value는 int, float, bool, String의 값을 가질 수 있습니다. 이때 measurement name, tag set의 경우 inverted index로서 조회속도가 좋습니다.
그리고 각 데이터에 필수 값인 Timestamp가 있고 나노 초 정도로 정밀한 값도 지정할 수 있습니다.
즉, 한 버킷내에 <measurement>,<tag set> <field set> <timestamp> 가 있는 구조이고 이들의 조합으로 Series가 구성됩니다.
Series
시리즈는 "시리즈 키"와 "시리즈 데이터"로 이루어져있습니다.
- 시리즈 키 : Measurement과 tag set의 유일한 조합입니다.
- 시리즈 데이터 : 시리즈 키와 관련된 timestamp와 field값들이 포함되어 있습니다.
Point
시리즈 키, 필드 값, timestamp를 포함하는 단일 데이터입니다. 따라서 . Series는 특정 시리즈 키의 모든 데이터 포인트의 집합이라고 할 수 있습니다.
샤딩
Shard Group Duration(샤드 그룹 보존 기간)에 따라 실제 데이터를 저장하는 Shard를 관리하고 인코딩 및 압축 저장됩니다. 이때 여러개의 series의 합으로 구성된 샤드그룹은 TSM방식을 기반으로 저장됩니다.
4. Influx DB 중요 동작
4-1. Task
Task는 Influx v2부터 생겨난 시계열 데이터를 처리하고 변환하기 위해 예약된 Flux 스크립트입니다. 활용 방법은 다음 단계를 따르게 됩니다.
1. task option 설정
- option task = {name: "downsample_5m_precision", every: 1h, offset: 0m}
- name: 그냥 이름
- every: 매 1시간마다 ( pm 2:30분에 최초 실행 → pm 3:00 최초 실행 후 1시간마다 실행)
- offset: 실행 딜레이를 줄 수 있음 (10m 이면 10분 딜레이) → 하지만 함수 적용 범위까지 딜레이 되지 않음 , 즉 실제 서비스에서 input을확실히 받고 task수행할 수 있음
- cron: "0 * * * *" 꼴로 배치처리 할 수 있음
2. 데이터 검색 및 필터링
from(bucket: "example-bucket")
|> range(start: -task.every)
|> filter(fn: (r) => r._measurement == "mem" and r.host == "myHost")- Flux문법에 맞추어 data 조회
- bucket: db 이름
- range: 조회할 시간 범위
- filter: 열 기준 검색조건
3. 데이터 처리 또는 변환, task 적용
option task = {name: "downsample_5m_precision", every: 1h, offset: 0m}
from(bucket: "example-bucket")
|> range(start: -task.every)
|> filter(fn: (r) => r._measurement == "mem" and r.host == "myHost")
|> aggregateWindow(every: 5m, fn: mean)- 일정한 간격으로 자동으로 스크립트를 실행
- 위의 예제는 1시간마다 5분간격의 평균 데이터를 계산함
- option
- every: 1h → 1시간 마다 task 실행
- aggregateWindow
- every: 5m → 5분 간격의 윈도우로 그룹화
- fn: mean → 평균 계산
4. Process data with invokable scripts
{
"name": "aggregate-intervals",
"description": "Group points into 5 minute windows and calculate the average of each
window.",
"script": "from(bucket: "example-bucket")\
|> range(start: -task.every)\
|> filter(fn: (r) => r._measurement == "mem" and r.host == "myHost")\
|> aggregateWindow(every: 5m, fn: mean)",
"language": "flux"
}- 그밖에도 task를 어떻게 생성하고 적용하는지 다양한 방법이 있음
- https://docs.influxdata.com/influxdb/cloud/process-data/manage-tasks/create-task/
5. 대상 정의
//...
|> to(bucket: "example-downsampled", org: "my-org")
//...- 다른 measurement 나 bucket에 저장할 수 있습니다.
- 위의 경우 to()를 활용해 다른 bucket에 저장하도록 지정한 경우 입니다.
6. Full example
// Full example Flux task script
option task = {name: "downsample_5m_precision", every: 1h, offset: 0m}
// Data source
from(bucket: "example-bucket")
|> range(start: -task.every)
|> filter(fn: (r) => r._measurement == "mem" and r.host == "myHost")
// Data processing
|> aggregateWindow(every: 5m, fn: mean)
// Data destination
|> to(bucket: "example-downsampled")
//Full example task with invokable script
{
"name": "aggregate-intervals-and-export",
"description": "Group points into 5 minute windows and calculate the average of each
window.",
"script": "from(bucket: "example-bucket")\
|> range(start: -task.every)\
|> filter(fn: (r) => r._measurement == "mem" and r.host == "myHost")\
// Data processing\
|> aggregateWindow(every: 5m, fn: mean)\
// Data destination\
|> to(bucket: "example-downsampled")",
"language": "flux"
}
위와 같은 Task처리를 통해 데이터를 처리한 값을 다운 샘플링하고 따로 보관하는 과정을 쉽게 이행할 수 있습니다.
4-2. 보존 정책
https://docs.influxdata.com/influxdb/v2/reference/internals/data-retention/
Data retention in InfluxDB | InfluxDB OSS v2 Documentation
Thank you for your feedback! Let us know what we can do better:
docs.influxdata.com
"만료된" 데이터를 자동으로 삭제하고 디스크 사용량을 최적화하기위한 정책입니다.
아무런 설정없는 기본 값은 매 30분마다 보존 정책 서비스를 실행시키게 됩니다. 이는 " storage-retention-check-interval "로 옵션을 설정할 수 있습니다.
보존 정책은 다음과같이 이루어집니다.
버킷 보유 기간
- 버킷이 데이터를 보존하는 기간.
- 정의된 보존기간을 초과하는 time stamp가 있는 버킷의 포인트가 대상이 됩니다.
샤드 그룹 지속시간
- 디스크에 저장할때 샤딩이 이루어지는데 이 샤드 그룹은 각자 샤드 그룹 듀레이션을 가지게 됩니다.
- 버킷을 생성하거나 업데이트할때 명시적으로 정의할 수 있지만 기본값은 다음과 같습니다.
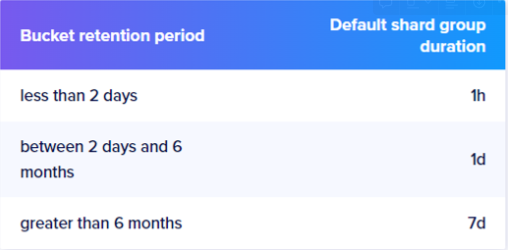
데이터 실제 삭제 시점
- 샤드 그룹 단위로 삭제가 진행됩니다.
- 샤드 그룹이 전체적으로 버킷 보존기간을 넘어서는 경우 해당 샤드그룹을 삭제합니다.
'DB > InfluxDB' 카테고리의 다른 글
| [InfluxDB] MySQL과 성능 비교 (0) | 2024.01.11 |
|---|