

0. 시작하며
https://nooroongzi.tistory.com/16
[InfluxDB] MySQL과 성능 비교
0. 시작하며 지난 포스팅에서 이론적으로 InfluxDB에 대해 알아보았습니다. 이번 포스팅에선 InfluxDB를 사용해보고 다음 두가지의 조회 속도에 대해 측정을 진행해 보려고 합니다. 쿼리레벨 연산과
nooroongzi.tistory.com
k6를 활용해 부하테스트의 지표로 DBMS의 성능을 테스트했던 과정을 공유합니다.
1. 진행 과정
처음 시도는 Naver에서 만든 오픈소스인 nGrinder를 사용하여 진행하고자 했습니다. nGrinder는 Java진영의 Junit5 기반의 Groovy언어로 스크립트를 작성할 수 있고, 한글로된 문서들이 많아 좀 더 쉽게 사용할 수 있을 줄 알았습니다만... 단순 도커이미지를 풀 받아 사용하는것으론 실행되지 않았습니다. 몇일간 고생하다 k6를 사용하여 진행하기로했고 nGrinder를 시도했던 과정은 아래에 접은글로 따로 정리하도록 하겠습니다.
nGrinder 사용기
결론 : 사용하기 어려움. 내부 라이브러리 호환성이 맞지 않는것같고, 여러 error가 있음..
nGrinder란?
nGrinder는 스크립트 작성, 테스트 실행, 모니터링 및 결과 보고서 생성기를 동시에 실행할 수 있는 스트레스 테스트용 플랫폼입니다. 오픈 소스 nGrinder는 불편함을 없애고 통합된 환경을 제공하여 스트레스 테스트를 쉽게 수행할 수 있는 방법을 제공합니다. Apache License, Version 2.0으로 라이센스가 부여되어 있습니다
구조
- Controller
- 성능 테스트기가 테스트 스크립트를 생성하고 테스트 실행을 구성할 수 있는 웹 애플리케이션입니다. 컨트롤러 도커 이미지 ngrinder/controller를 가져올 수 있습니다.
- Agent
- 부하를 생성하는 가상 사용자 생성기입니다. 에이전트 도커 이미지 ngrinder/agent를 가져올 수 있습니다.
nGrinder 설치
Controller
docker pull ngrinder/controller:3.5.8
docker run -d -v ~/ngrinder-controller:/opt/ngrinder-controller -p 80:80 -p 16001:16001 -p 12000-12009:12000-12009 ngrinder/controller:3.5.8
Agent
docker pull ngrinder/agent:3.5.8
docker run -v ~/ngrinder-agent:/opt/ngrinder-agent -d ngrinder/agent:3.5.8 controller_ip:controller_web_port
위처럼 도커 이미지를 pull받고 컨테이너를 실행할 수 있습니다. 이때 동일한 시스템에서 실행 중인 도커는 추가 도커 네트워킹 솔루션을 사용하지 않고는 서로 통신할 수 없으므로 컨트롤러가 실행 중인 물리적/가상 시스템과 다른 물리적 시스템에서 에이전트를 실행해야 합니다.
또한 에이전트는 로드를 생성하기 위해 시스템의 전체 리소스를 사용할 수 있으므로 컨트롤러가 설치된 것과 물리적으로 다른 시스템에서 nGrinder 에이전트 컨테이너를 실행하는 것이 좋습니다.
이때 Agent의 docker container 실행 명령에서 controller_ip:controller_web_port 설정을 통해 Controller에 Agent를 등록할 수 있습니다.( 헤더의 admin(계정이름)의 드롭다운중 Agent Management가 있는데 여기서 Agent의 등록 여부를 확인할 수 있음 )
컨트롤러는 /opt/ngrinder-controller 아래에 데이터 폴더를 생성하여 테스트 기록 및 구성 데이터를 유지 관리합니다. 데이터를 지속적으로 유지하려면 컨테이너의 /opt/ngrinder-controller를 호스트의 폴더에 매핑해야 합니다.
컨트롤러 접속

처음 접속하면 위와 같은 화면을 보실 수 있습니다. 이때 초기 ID, PW는 admin 입니다. 입력하고 접속하면 아래 화면을 보실 수 있습니다.
위 헤더를 통해 성능 테스트를 진행하고, 스크립트를 작성하는 페이지로 이동할 수 있습니다.
스크립트 작성
Groovy와 Jython을 지원하고 간단한 딸깍딸깍으로 스크립트를 만들어줍니다.
성능테스트 실행
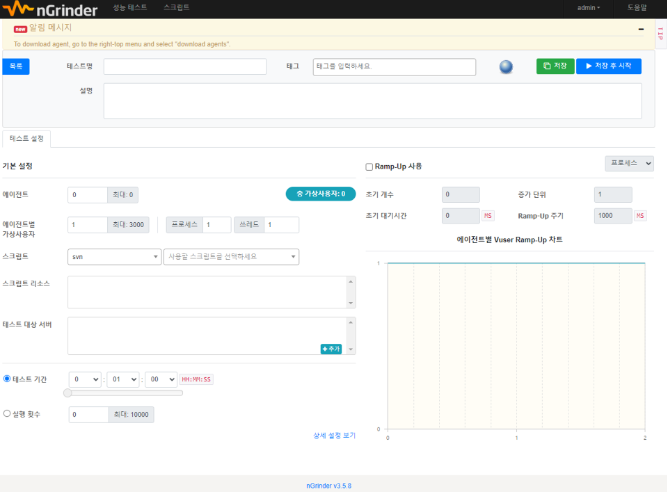
스크립트를 만들고 성능 테스트를 진행할 수 있습니다. 각 항목은 다음과 같이 이해할 수 있습니다.
- 테스트 명: 테스트 제목, 이걸로 검색 가능
- 태그: 태깅 기능, 테스트 목록에서 빠른 검색 가능
- 저장, 시작 기능
- 에이전트: 테스트에 사용할 에이전트 개수와 테스트를 진행할 지역을 설정할 수 있음
- 에이전트별 가상 사용자: 에이전트별 가상 사용자 수 지정 가능
- 스크립트: 테스트에 사용할 스크입트를 선택
- 스크립트 리소스: 테스트 실행시 이파일들은 에이전트로 동시 전송됨
- 테스트 대상 서버
- 테스트 대상 서버를 표시함
- host명과 IP를 동시에 설정시 마치 DNS처럼 사용할 수 있음.
- ngrinder 모니터가 설치되어있다면 현재시스템의 성틍 데이터를 수집한다.
- 테스트 기간
- 지정한 기간동안 테스트가 실행된다
- 테스트 기간과 실행 횟수 둘 중 하나를 선택할 수 있음
- 실행 횟수
- 쓰레드당 테스트 반복횟수를 지정함.
- 상세 설정에서 해당 테스트 샘플링 주기, 샘플링 무시 횟수, 파일 안전 전송, 파라미터등의 고급 기능을 설정할 수 있음
- Ramp-up
- 천천히 테스트가 실행되도록 Ramp-up을 설정할 수 있음
- 프로세스 기준 또는 쓰레드 기준으로 Ramp Up이 가능함
- 초기 개수, 증가 단위, 초기 대기시간, Ramp UP 주기를 설정할 수 있음
- 초기 개수 : 초기 Process/Thread 수
- 증가 단위 : Process/Thread를 몇 개씩 증가시킬 건지
- 초기 대기 시간
- Ramp UP 주기 : 얼마 주기로 증가시킬 건지
저는 위 Controller와 Agent를 각각 AWS medium ubuntu 서버에 올려서 진행해보았으나 다음과 같은 에러가 있었습니다.
발생한 에러
1. 스크립트 인증 에러
3.5.8 version에서 스크립트 인증 에러가 발생합니다. github discussion이나 구글링을 통해 다음과 같은 해결책을 찾을 수 있었습니다.
- k8s 환경에서 내부 라이브러리 호환성을 업그레이드하여 이미지를 재빌드한다.
- 버전을 다운그레이드한다.
먼저 1번 의경우 쿠버네티스 환경을 새롭게 구축하는건 제가 다뤄본적이 없기에.. 무리라고 생각하여 소스코드를 클론받아 내부 라이브러리 호환성을 맞춰 이미지를 재빌드해 사용해 보았습니다만.. 이또한 문제가 해결되지 않았습니다.
2번의 경우 3.5.3버전 까지 다운그레이드하여 진행해보았으나 이경우엔

이러한 경고 메시지가 등장하며 여전히 스크립트 인증이 진행되지 않았습니다..
2. windows 10 Docker + WSL2 integration 환경에서 SVN 라이브러리 에러발생
1번 에러를 겪고 로컬 환경으로 옮겨 Controller를 실행해봤습니다. 그러나 저의 desktop 이 window 10인지라... 위와 같은 에러로 인해 스크립트 생성이 불가능 했습니다.
이러한 이유들로 K6를 사용하기로 변경하였습니다.
https://grafana.com/docs/k6/latest/get-started/
Get started | Grafana k6 documentation
Thank you! Your message has been received!
grafana.com
대부분 위 공식문서를 참조했고 잘 구성되어있어 쉽게 사용할 수 있었습니다. 저는 도커를 사용하여 진행하겠습니다.
K6 install
docker pull grafana/k6
먼저 K6이미지를 받고 스크립트를 작성합니다.
스크립트 작성
import http from 'k6/http';
import { check } from 'k6';
import { htmlReport } from "https://raw.githubusercontent.com/benc-uk/k6-reporter/main/dist/bundle.js";
export const options = {
vus: 100,
duration: '180s',
};
const urls = [
'http://your_ip_addr:8080/bitcoin/avg-code',
'http://your_ip_addr:8080/bitcoin/avg-query',
// url을 추가 할 수 있습니다.
];
export default function () {
urls.forEach(url => {
const payload = JSON.stringify({
startTime: '2023-12-01T00:00:00',
endTime: '2023-12-25T00:00:00'
});
const params = {
headers: {
'Content-Type': 'application/json',
},
};
let response = http.post(url, payload, params);
check(response, { 'status was 200': r => r.status === 200 });
});
}
export function handleSummary(data) {
return {
"summary.html": htmlReport(data),
};
}이런식으로 먼저 option을 통해 가상의 유저(vus)수와 테스트를 진행할 기간(duration)을 정할 수 있습니다. 해당기간 동안 가상의 유저가 테스트를 진행하게 됩니다.
저는 테스트가 끝나면 summary를 html형식으로 받도록 함수를 추가해주었고 다음과 같은식으로 확인해볼 수 있습니다.

summary 설정이 없다면 기본적으로 다음과 같이 terminal을 통해 결과가 출력됩니다.

이외에도 json이나 다른 형식으로 결과를 받을 수도 있습니다.
2. 결과
옵션
- vus: 100
- duration: 180s
InfluxDB
- 코드 레벨 필터링 (전체 평균 조회)
- Total Req: 2208
- 평균 소요 시간: 8340.88ms
- 쿼리 레벨 필터링 (전체 평균 조회)
- Total Req: 24341
- 평균 소요 시간: 740.53 ms
- 코드 레벨 필터링 (시간별 평균 조회)
- Total Req: 2192
- 평균 소요 시간: 8398.61 ms
- 쿼리 리벨 필터링 (시간별 평균 조회)
- Total Req: 18961
- 평균 소요 시간: 951.22 ms
MySQL
- 코드 레벨 필터링 (전체 평균 조회)
- Total Req: 3812
- 평균 소요 시간: 4787.32 ms
- 쿼리 레벨 필터링 (전체 평균 조회)
- Total Req: 15417
- 평균 소요 시간: 1171.00 ms
- 코드 레벨 필터링 (시간별 평균 조회)
- Total Req: 3671
- 평균 소요 시간: 4971.61 ms
- 쿼리 리벨 필터링 (시간별 평균 조회)
- Total Req: 10745
- 평균 소요 시간: 1682.67 ms
3. 결론
쿼리레벨 필터링을 적용할때 InfluxDB가 MySQL보다 최대 약 43.47% 빠르게 나타났습니다.
반대로 코드레벨 필터링을 적용할 경우 MySQL이 42.6 % 더 빠른 결과를 나타냈습니다.
제가 postman으로 수작업으로 결과를 도출한 경우와 오차가 매우 큰 결과여서 놀랐습니다.
이전 포스팅에서 설명 했지만 코드 레벨 필터링 API의 경우 의도적으로 쿼리 레벨 필터링을 적용하지 않아 매우 부자연스러운 코드입니다. 따라서 일반적으로 쿼리 레벨 필터링을 실시하고, 시계열DB에 적합한 데이터를 다룰 경우 InfluxDB를 사용하는것만으로도 높은 성능 향상을 기대할 수 있을거 같습니다.